Using RunPod hosted LLMs for text generation via an API
Introduction
Following on from my previous post about RunPod I wanted to see if I could use the platform to host LLMs that I could then access via an API. This would allow me to programmatically submit inference requests to RunPod and receive the generated text back in a format that I could then use as part of a larger application.
Prerequisites
Sign up for a RunPod account here. You’ll need to provide your name, email address, and password. Once you’ve signed up, you’ll be able to access the RunPod dashboard.
Running an LLM with Text Generation WebUI
- From the
Podstab in the RunPod dashboard, clickNew Pod. - Select your required number and model of GPUs from the available list. RTX 4090s are powerful enough to run most quantised LLMs, but you may need to use a RTX 6000 or larger for some models.
- Under your selected GPU, click
Deploy. - I recommend using TheBloke’s One-Click UI & API template as this comes pre-installed with the required dependencies for running LLMs. If it’s not already selected, use the UI to search for the correct template and select it.
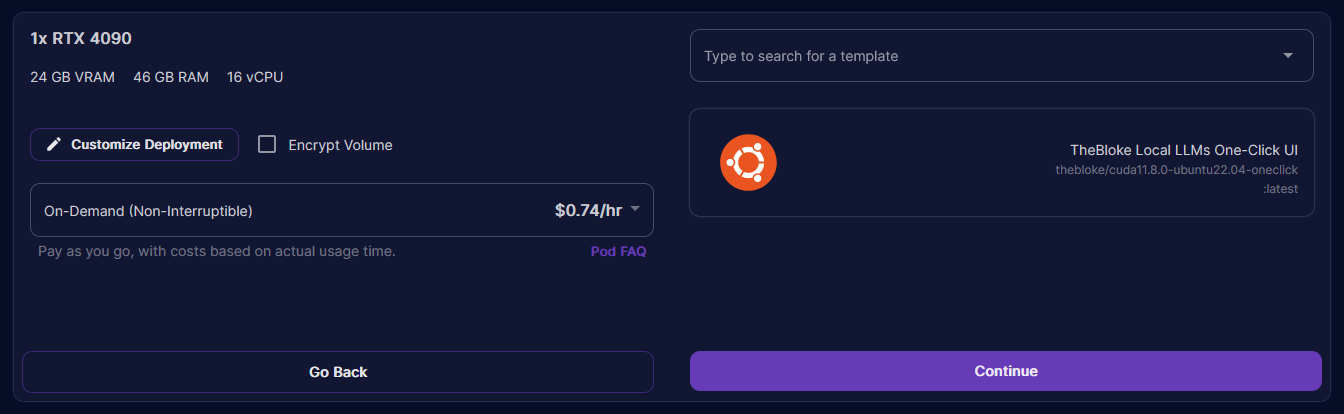
❗ Important: If you want to expose the Text Generation WebUI API, you need to select the
One-Click UI & APItemplate. If you select theOne-Click UItemplate, the API will not be exposed. - Click
Continueand thenDeploy. After a couple of minutes, your pod will be ready to use. - Once the pod is in a
Runningstate, clickConnectto open theConnection Options. - Click
Connect to HTTP Service [Port 7860]to launch TGWUI. - In TGWUI, select the
Modeltab. You should now see a UI similar to the one below.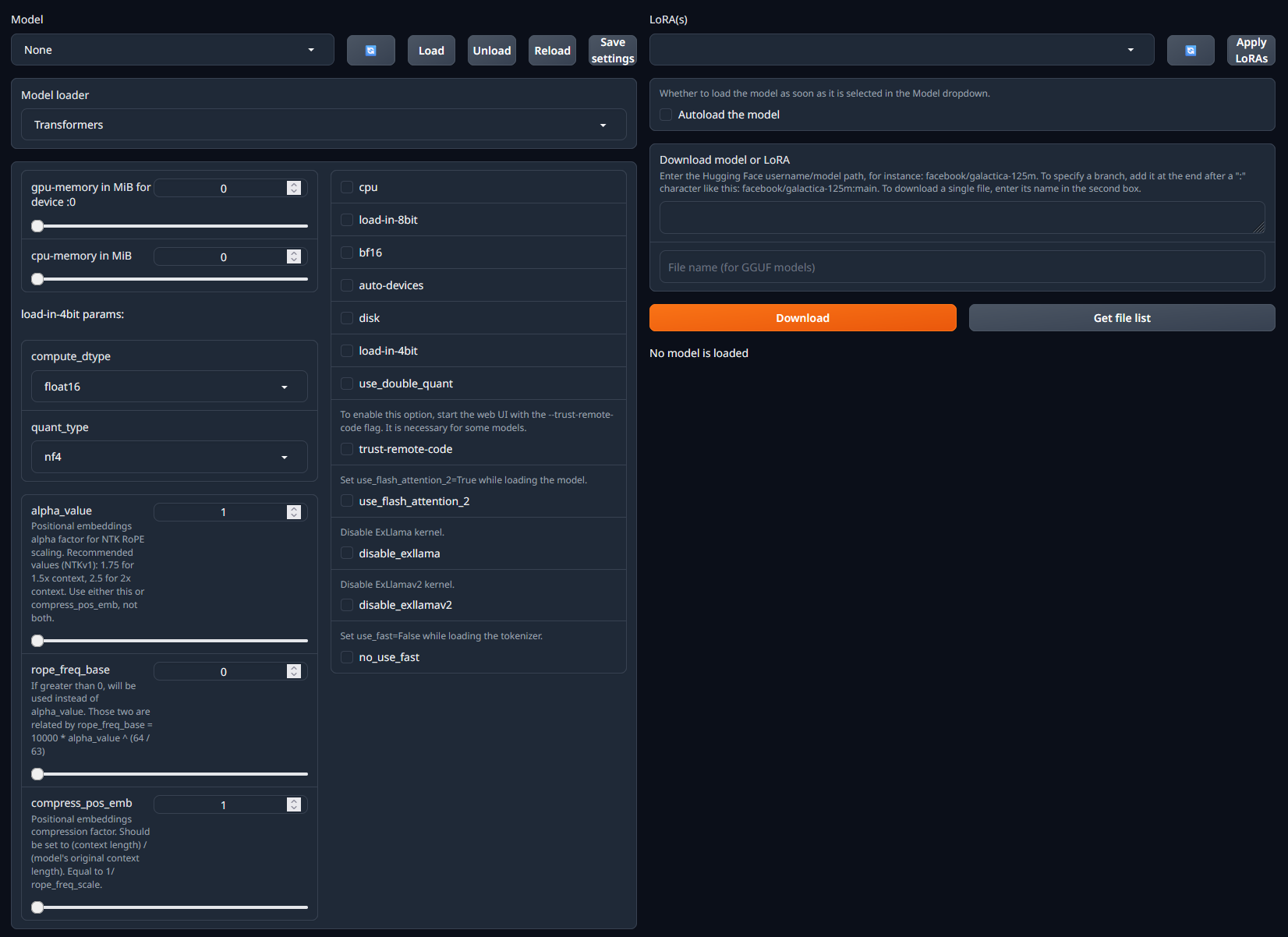
- Within the
Download model or LoRAsection, paste in the username/model path from HuggingFace. For example, if you wanted to run the dolphin-2_6-phi-2 model, you would paste incognitivecomputations/dolphin-2_6-phi-2. - Click
Downloadto download the model. - Once the model has downloaded, refresh the list of available models in the dropdown menu in the top-left of the page. 12. Select the model you want to run and click
Load. - At this point you may see some error messages displayed. These are mostly caused by missing / incorrect configuration settings. See the model details page on HuggingFace or the Common Issues section below for more information on how to resolve these.
- With the model loaded, it’s time to look at how to submit inference requests to the model via the API.
Submitting inference requests to a RunPod hosted API endpoint
Use the following code as a starting point and tailor it to your requirements. The comments in the code indicate which elements can / should be updated.
import requests
import json
url = "https://<your-runpod-pod-id>-5000.proxy.runpod.net/v1/completions" # Update with your API endpoint
headers = {
"Content-Type": "application/json"
}
message = "How can I make a cake?" # Update with your message
data = {
# This uses the ChatML prompt format, you may need to update it based on the requirements of the model you're using
"prompt": """<|im_start|>system
You are Dolphin, a helpful AI assistant.<|im_end|>
<|im_start|>user
{}<|im_end|>
<|im_start|>assistant""".format(message),
"max_tokens": 200, # Update max tokens and hyperparameters as required
"temperature": 0.7,
"top_p": 0.9,
"seed": 10
}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.text)